1. 简介
之前介绍过红黑树,今天再介绍一种树——B树。它与红黑树有许多类似的地方,比如都是平衡搜索树,当它们在功能和结构上却有较大的差别。
从功能上看,B树是为磁盘或其他存储设备设计的,能够有效的降低磁盘的I/O操作数,因此我们经常看到有许多数据库系统使用B树或B树的变种来储存数据结构;从结构上看,B树的结点可以有很多孩子,从数个到数千个,这通常依赖于所使用的磁盘的单元特性。
如下图,给出了一棵高度为2包含10亿多个关键字的B树。

从图中我们可以发现,如果一个内部结点包含n个关键字,那么结点就有n+1个孩子。 例如,根结点有1个关键字M,它有2个孩子;它的左孩子包含2个关键字,可以看到它有3个孩子。之所以是n+1个孩子,是因为B树的结点中的关键字是分割点,n个关键字正好分隔出n+1个子域,每个子域都对应一个孩子。
2. 辅存上的数据结构
在之前我们提到,B树是为磁盘或其他存储设备设计的。因此,在正式介绍B树之前,我们有必要弄清楚为什么针对磁盘设计的数据结构有别于针对随机访问的主存所设计的数据结构,只有这样才能更好理解B树的优势。
我们知道,磁盘比主存便宜且有更多的容量,但是它比主存要慢许多,通常会慢出4~5个数量级。为了提高磁盘的读写效率,我们在读写磁盘时,会一次存取多个数据而不是一个。在磁盘中,信息被分为一系列相等大小的在柱面内连续出现的位页面(page),每次磁盘读或写一个或多个完整的页面。通常,一页的长度可能是字节。
因此,在本篇博客中,我们对运行时间的衡量主要从以下两个方面考虑:
- 磁盘存取次数
- CPU时间
我们用读出或写入磁盘的信息的页数来衡量磁盘存取的次数。注意到,磁盘存取时间并不是常量——它与当前磁道和所需磁道之间的距离以及磁盘的初始旋转状态有关,但是为了简单起见,我们仍然使用读或写的页数作为磁盘存取总时间的近似值。
在一个典型的B树应用中,所需处理的数据非常大,以至于所有的数据无法一次转入主存。B树算法讲所需页面从磁盘复制到主存,若进行了修改,之后则会写回磁盘。因此,B树算法在任何时刻都只需要在主存中保存一定数量的页面,主存的大小并不限制被处理的B树的大小。
下面用几行伪代码来模拟对磁盘的操作。设x为指向一个对象的指针,我们在使用x(指向的对象)时,需要先判断x指向的对象是否在主存中,若在则可以直接使用;否则需要将其从磁盘读入到主存,然后才能使用。
x = a pointer to some object
DISK-READ(x) // 将x读入主存,若x已经在主存中,则该操作相当于空操作
modify x
DISK-WRITE(x) // 将x写回主存,若x未修改,则该操作相当于空操作
由上我们看出,一个B树算法的运行时间主要由它所执行的DISK-READ和DISK-WRITE操作的次数决定,所以我们希望这些操作能够读或写尽可能多的信息。因此,一个B树结点通常和一个完整磁盘页一样大,并且磁盘页的大小限制了一个B树结点可以含有的孩子的个数。
如下图是一棵高度为2(这里计算高度时不计算根结点)的B树,它的每个结点有1000个关键字,因此分支因子(孩子的个数)为1001,于是它可以储存个关键字,其数量超过10亿。我们如果将根结点保存在主存中,那么在查找树中任意一个关键字时,至多只需要读取2次磁盘。
3. B树的定义
下面正式给出B树的定义。一棵B树必须具备如下性质:
- 每个结点有如下属性:
- 。它表示储存在 中的关键字的个数;
- 。它们表示的个关键字,以非降序存放,即;
- 。它是一个布尔值,如果是叶结点,它为TRUE;否则为FALSE;
- 。它们是指向自己孩子的指针。如果该结点是叶节点,则没有这些属性。
- 关键字对存储在各子树中的关键字范围进行分割,即满足:。其中,表示任意一个储存在以为根的子树中的关键字。
- 每个叶结点具有相同的深度,即叶的高度。
- 每个结点所包含的关键的个数有上下界。用一个被称为最小度数的固定整数来表示这些界:
- 下界:除了根结点以外的每个结点必须至少有个关键字。因此,除了根结点外的每个内部结点至少有个孩子。
- 上界:每个结点至多包含个关键字。因此,一个内部结点至多可能有个孩子。当一个结点恰好有个关键字时,称该结点为**满的(full)**。
下面用Java实现以上定义:
import java.util.List;
/**
* B树类
*
* @param <K> B树储存元素的类型
*/
public class BTree<K extends Comparable<K>> {
private BNode<K> root;
private int height;
private int minDegree;
/**
* B树的结点类
*
* @param <K>
*/
public static class BNode<K extends Comparable<K>> {
private List<K> keys;
private List<BNode> children;
private int size;
private boolean leaf;
}
}
限于篇幅,上述代码省略了setter和getter方法;我们抽象出代表结点的BNode类,作为表示B树的类BTree的内部类;它们具有如上面定义所说的各属性,只是在属性名上略有不同,会意就好;并且由于B树要求结点包含的关键字是按非逆序排列的,因此我们定义的泛型K必须实现了Comparable接口。
根据以上定义,当时的B树是最简单的。此时树的每个内部结点只可能有2个、3个或4个孩子,我们称它为2-3-4树。显然的,t的取值越大,B树的高度也就越小。事实上,B树的高度与其包含的关键字的个数以及它的最小度数有如下的关系:
如果,那么对于任意一棵包含个关键字、高度为、最小度树 的B树有:
证明很简单,因为B树的根结点至少包含1个关键字,而其他的结点至少包含个关键字,因此除根结点外的每个结点都有个孩子,于是有:
4. B树上的基本操作
同其它的二叉搜索树一样,我们主要关心B树的search、create、insert和delete操作。首先做两个约定:
- B树的根结点始终在主存中,这样我们可以直接引用根结点而不需要执行DISK-READ操作;但是若根结点被修改,我们需要对其执行DISK-WRITE操作。
- 任何被当做参数的结点在被传递之前,都要对它们先做一次DISK-READ操作。
4.1 Search 操作
首先考察搜索操作。它与普通的二叉搜索类似,只不过它多了几个“叉”,需要进行多次判断。
记B树的根结点(的指针)为,现在要在中搜索关键字。如果在树中,则返回对应结点(的指针)和的下标组成的有序对;否则返回空。
下面给出Java的实现:
private SearchResult<K> search(BNode<K> currentNode, K k) {
int i = 0;
while (i < currentNode.size && k.compareTo(currentNode.getKeys().get(i)) > 0) {
i++;
}
if (i < currentNode.size && k.compareTo(currentNode.getKeys().get(i)) == 0)
return new SearchResult<K>(currentNode, i);
if (currentNode.leaf)
return null;
// DISK-READ(currentNode.getChildren()[i])
return search(currentNode.getChildren().get(i), k);
}
public static class SearchResult<K extends Comparable<K>> {
public BNode<K> bNode;
public int keyIndex;
public SearchResult(BNode<K> bNode, int keyIndex) {
this.bNode = bNode;
this.keyIndex = keyIndex;
}
}
Search用了递归的操作:每层递归都会从左往右(从小到大)依次比较当前结点的第i(从0起)个关键子与待搜索的关键字k的大小,直到第i个关键字不小于k时,若刚好等于k,则表示搜索到了,直接返回;若未找到,则会将第i个孩子作为当前结点,递归继续查找,即继续到以第i个孩子为根结点的子树中查找。实际上,在文章开头给出的一棵关键字为字母的B树中,颜色较浅的结点即为我们在搜索关键字R时,需要搜索的结点。
由此我们不难看出,上述search过程访问磁盘的次数为;而每层递归调用中,循环操作的时间代价为(因为除根结点外,每个结点的关键字个数为与之间)。因此,总的时间代价为。
4.2 Create 操作
为构造一棵B树,我们先用create方法来创建一棵空树(根结点为空),然后调用insert操作来添加一个新的关键字。这两个过程有一个公共的过程,即allocate-node,它在时间内为一个新结点分配一个磁盘页。
由于create操作很简单,下面只给出伪代码:
create(T)
x = allocate-node()
x.leaf = TRUE
x.n = 0
DISK-WRITE(x)
T.root = x
4.3 Insert 操作
和普通二叉搜索树一样,我们必须先根据关键字找到要插入的位置。但和普通二叉搜索树直接创建一个新的叶结点然后将其插入不同,B树不能直接插入,因为这样得到的B树可能会不合法。
B数的做法是,不去新建叶结点,而是将新的关键字插入到已经存在的叶结点上。但是,若该叶结点已经是满的,再插入一个新的结点也会导致非法。
因此,B树在插入前,先判断结点是否是满的,若非满,那就直接插入;否则我们就将该结点一分为二,分裂为两个结点,而中间的关键字插入到其父结点中。下图演示了该过程:

注意:上图截取自《算法导论(第三版),机械工业出版社》,其中右侧部分中的关键字W和S的顺序弄反了。
结合上图,满结点的分裂过程应该很容易理解。在图中,B树的最小度数,因此左侧中包含关键字的结点是满的。于是我们先将处在中间位置的关键字提升到其父结点中,然后结点一分为二,正如上图右侧所示。
需要注意的是,很有可能父结点也是满的,当我们在将子节点的中间关键字提升至父结点时,父结点又变的不合法了,我们又需要用同样的方法处理父结点,于是形成了自底向上的顺序分裂。既然如此,我们干脆这么做:在逐层查找待插入关键的位置时,只要遇到满结点,就进行分裂,即采用自顶向下的顺序分裂,这样就不会遇到提升关键字导致父结点不合法的问题。
特别地,对于满的根结点,处理方式稍微有些不同,如下图:
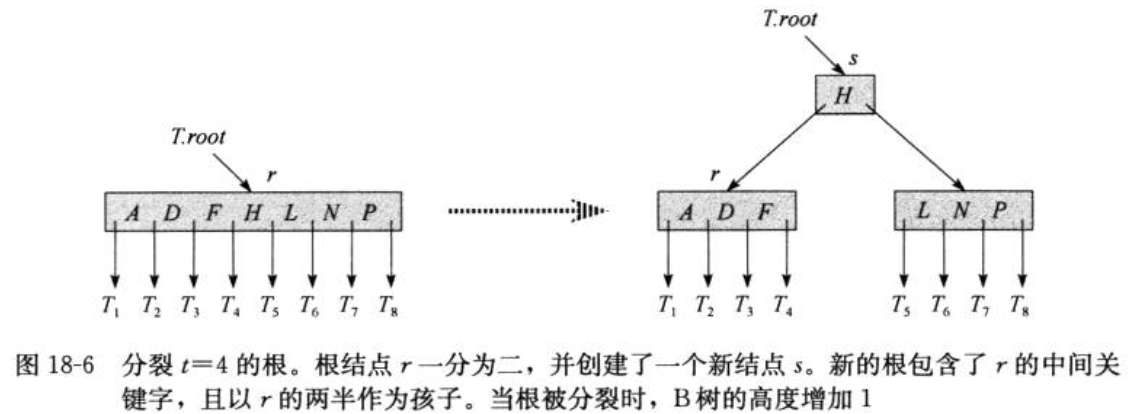
图中描述过程,实际上包含两步,首先是新建一个空的根结点,之后的步骤跟其他普通的结点分裂一样。由上我们可以看出,对满的非根结点的分裂不会使B树的高度增加,导致B树高度增加的唯一方式是对根结点的分裂。
下面给出分裂过程的Java代码:
/**
* 分裂node的第i个子结点
*
* @param node 非满的内部结点
* @param i 第i个子结点
*/
private void splitNode(BNode<K> node, int i) {
BNode<K> childNode = node.getChildAt(i);
int fullSize = childNode.getSize();
// 从满结点childNode中截取后半部分
List<K> newNodeKeys = childNode.getKeys().subList(fullSize / 2 + 1, fullSize - 1);
List<BNode<K>> newNodeChildren = childNode.getChildren().subList((fullSize + 1) / 2, fullSize);
BNode<K> newNode = new BNode<>(newNodeKeys, newNodeChildren, childNode.leaf);
// 重新设置满结点childNode的size,而不必截取掉后半部分
childNode.setSize(fullSize / 2);
// 将childNode的中间关键字插入node中
K middle = childNode.getKeyAt(fullSize / 2);
node.getKeys().add(i, middle);
// 将分裂出的结点newNodeKeys挂到node中
node.getChildren().add(i + 1, newNode);
// 更新size
node.setSize(node.getSize() + 1);
// 写入磁盘
// DISK-WRITE(newNode)
// DISK-WRITE(childNode)
// DISK-WRITE(node)
}
代码中的注释基本给出的每部操作的目的,这里不再赘述。实现了分裂过程,我们接下来就可以写insert过程了:
/**
* 插入关键字
*
* @param key 待插入的关键字
*/
public void insert(K key) {
// 判断根结点是否是满的
if (root.getSize() == 2 * minDegree - 1) {
// 若是满的,则构造出一个空的结点,作为新的根结点
LinkedList<K> newRootKeys = new LinkedList<K>();
LinkedList<BNode<K>> newRootChildren = new LinkedList<BNode<K>>();
newRootChildren.add(root);
root = new BNode<K>(newRootKeys, newRootChildren, false);
splitNode(root, 0);
height++;
}
insertNonFull(root, key);
}
以上代码中,首先判断根结点是否满了,若满了,就构造出一个新的根结点,将以前的根结点挂到其下,注意此时新的根结点中还没有关键字,接着调用splitNode方法去分裂旧的根结点,这样处理下来,就能保证根结点是非满状态了。以下是splitNode过程的Java代码:
/**
* 分裂node的第i个子结点
*
* @param node 待分裂结点的父结点(注意不是待分裂的结点)
* @param i 第i个子结点
*/
private void splitNode(BNode<K> node, int i) {
BNode<K> childNode = node.getChildAt(i);
int childKeysSize = childNode.getSize();
int childChildrenSize = childNode.getChildren().size();
// 从满结点childNode中截取后半部分作为分裂的右结点
LinkedList<K> rightNodeKeys = new LinkedList<K>(childNode.getKeys().subList(childKeysSize / 2 + 1, childKeysSize));
LinkedList<BNode<K>> rightNodeChildren = childNode.getChildren().isEmpty() ? new LinkedList<BNode<K>>() : new LinkedList<>(childNode.getChildren().subList((childChildrenSize + 1) / 2, childChildrenSize));
BNode<K> rightNode = new BNode<>(rightNodeKeys, rightNodeChildren, childNode.leaf);
// 从满结点childNode中截取前半部分作为分裂的左结点
LinkedList<K> leftNodeKeys = new LinkedList<K>(childNode.getKeys().subList(0, childKeysSize / 2));
LinkedList<BNode<K>> leftNodeChildren = childNode.getChildren().isEmpty() ? new LinkedList<BNode<K>>() : new LinkedList<>(childNode.getChildren().subList(0, (childKeysSize + 1) / 2));
BNode<K> leftNode = new BNode<>(leftNodeKeys, leftNodeChildren, childNode.leaf);
node.getChildren().set(i, leftNode);
// 将childNode的中间关键字插入node中
K middle = childNode.getKeyAt(childKeysSize / 2);
node.getKeys().add(i, middle);
// 将分裂出的结点newNodeKeys挂到node中
node.getChildren().add(i + 1, rightNode);
// 写入磁盘
// DISK-WRITE(newNode)
// DISK-WRITE(childNode)
// DISK-WRITE(node)
}
有了上述保证,我们就可以大胆地调用insertNonFull方法去插入关键字了。下面给出insertNonFull的Java实现代码:
/**
* 将关键字k插入到以node为根结点的子树,必须保证node结点不是满的
*
* @param node 要插入关键字的子树的根结点(必须保证node结点不是满的)
* @param key 待插入的关键字
*/
private void insertNonFull(BNode<K> node, K key) {
int i = node.getSize() - 1;
if (node.leaf) {
// 若node是叶结点,直接将关键字插入到合适的位置(因为已经保证node结点是非满的)
while (i > -1 && key.compareTo(node.getKeyAt(i)) < 0) {
i--;
}
node.getKeys().add(i + 1, key);
// DISK-WRITE(node)
return;
}
// 若node不是叶结点,我们需要逐层下降(直到降到叶结点)的去找到key的合适位置
while (i > -1 && key.compareTo(node.getKeyAt(i)) < 0) {
i--;
}
i++;
// 判断node的第i个子结点是否是满的
if (node.getChildAt(i).getSize() == 2 * minDegree - 1) {
// 若是满的,分裂
splitNode(node, i);
// 判断应该沿分裂后的哪一路下降
if (key.compareTo(node.getKeyAt(i)) > 0)
i++;
}
// 到了这一步,node.getChildAt(i)一定不是满的,直接递归下降
insertNonFull(node.getChildAt(i), key);
}
正如insertNonFull方法的名字那样,我们在调用该方法时,必须保证其参数中node代表的结点是非满的,这也是为什么在insert方法中,要保证根结点非满的原因。
insertNonFull方法实际上是一个递归操作,它不断的迭代子树,子树的高度每迭代一次就减1,直至子树就是一个叶子结点。
4.4 Delete 操作
B树的删除操作同样也较简单搜索树复杂,因为它不仅可以删除叶结点中的关键字,而且可从内部结点中删除关键字。和添加结点必须保证结点中的关键字不能过多一样,当从结点中删除关键字后,我们还要保证结点中的关键字不能够太少。我们可以将删除操作看做是增加操作的“逆过程”。下面给出删除操作的算法。
该算法实际上是一个递归算法,过程DELETE接受一个结点参数和一个关键字参数,它表示从以为根的子树中删除关键字。该过程必须保证无论何时,**参数表示的结点中的关键字个数至少为最小度数**,它比通常B树要求的最小关键字个数多1个以上,这样能够使得我们可以把中的一个关键字移动到子结点中,因此,我们可以采用递归下降的方法将关键字从树中删除,而不需要任何“向上回溯”(但有一个例外,之后会看到)。
为了以下说明的方便,我们为树中的节点编上坐标,规定 表示树 中,第 层,从左往右数,第 个结点。例如:根结点的坐标是 ;另外,需要提前说明的是以下例子中树的最小度数 。
下面分两大类情况讨论:
一、待删除的关键字在中
其中又分 2 小类情况:
若是叶节点,直接从中删除。
这种情况比较简单,以下面 2 张图为例,我们即将删除第 1 张图中 𝑇(3,2) 结点中的关键字 𝐹 ,删除后的 B 树如第 2 张图片所示:
.png "图a")
.png "图b")
- 若是内部结点,又分以下3种情况讨论:
情形A: 如果结点中前于的子结点至少包含个关键字,则找出在以为根的子树中的前驱,递归的删除,并在中用代替(注意递归的意思)。
这个直接阅读理解起来,可能比较困难,我们来看一个例子:
.png "图c")
从图b到图c,可以发现,删除了结点中的关键字,由于的左子树的根结点,即结点中有三个结点(大于个),因此我们将其中的关键字(的前驱)提升到原的位置,这样原来所在的结点只剩下,仍然是合法的,但这样导致其子结点“多”出了一个,我们还需将其子结点中的某个关键字提升到该结点中,之后又要处理子子结点……
到这时候你可能已经发现,这其实是一个递归的过程。抛开关键字提升的过程,我们实际上就是在做删除操作:首先删除,接下来删除其子结点中的,再接下来是删除其子子结点的某个关键字……于是我们在实现的时候,可以用递归的操作去完成它。
情形B: 如果前于的子结点中的关键字个数少于,但后于的子结点中的关键字至少有个,则找出在以为根的子树的后驱,递归地删除,并在中用代替。
该情况和A类似,这里不在赘述。
情形C: 若
A和B都不满足,即关键字的左右子结点中的关键字的个数均小于t(为),则将和的全部合并进,然后问题变为了从中删除。我们同样用递归的方式来进行以上操作。
举个例子,比如想要删除上面图 (c) 中 结点中的关键字 。
先检查 𝐺 的左右孩子 𝑇(3,2),𝑇(3,3) 发现,它们包含的关键字均小于 𝑡,于是将 关键字 𝐺,以及结点 𝑇(3,3) 中的全部关键字( 𝐽,𝐾)移动到 𝑇(3,2) 中,这样 𝑇(3,2) 中便包含 𝐷,𝐸,𝐺,𝐽,𝐾 5 个关键字。现在问题就转变为从结点 𝑇(3,2) 中删除关键字 𝐺 ,这可以采用前面讨论的过程来解决。
最终得到的结果如下图所示:
.png "图d")
二、待删除的关键字不在中:
在该类情况下,我们假设关键字在以的子结点为根的子树中(若关键字确实在树中)。
情形D: 如果以及的所有相邻兄弟都只包含个结点,则将与一个兄弟结点合并,并将的一个关键字移动到新合并的结点,成为中间关键字。
举例说明。假如在上面的图(d) 中,我们打算删除关键字 𝐷。
先从根结点(𝑥)开始向下搜寻包含关键字 𝐷 的结点。显然,接下来会选择到结点 𝑇(2,1) 进行搜寻工作。但注意,此时结点 𝑇(2,1) 只包含 2 个关键字(𝐶,𝐿),而其所有的兄弟结点也都只包含 2 个关键字,因此需要将结点 𝑥 中的一个关键字(只有 𝑃),以及兄弟结点 𝑇(2,2) 中的全部关键字移动到 𝑇(2,1) 中,并删除该兄弟结点和结点 𝑥(若此时结点 𝑥 不包含任何关键字)。
删除后的情形如下图所示:
.png "图e")
情形E: 如果只包含个关键字,但它的一个相邻的兄弟至少包含个关键字,则将中的某个关键字降至,将相邻的一个兄弟中的关键字提升至,并将该兄弟相应的孩子指针也移动到中。
例如,想要删除上图(e')中的关键字 𝐵。在根结点(𝑥)开始向下搜寻时,发现待“降落”的下级结点 𝑇(2,1) 包含 2 个关键字,而其兄弟结点 𝑇(2,2) 包含 3 个关键字,因此,将 𝑥 中的关键字 𝐶 下降到结点 𝑇(2,1)中,再将结点 𝑇(2,2) 中的关键字 𝐸 提升到刚才下降的关键字 𝐶 的位置。最后还需要将关键字 𝐸 的左孩子移动到 𝑇(2,1) 中。
删除后的情形如下图所示:
.png)
以上便是整个删除操作的算法,下面给出具体的Java实现代码:
/**
* 从以node为根结点的子树中删除key
*
* @param node 子树的根结点(必须保证其中的关键字数至少为t)
* @param key 要删除的关键字
* @return 是否删除成功
*/
private boolean delete(BNode<K> node, K key) {
// node是叶结点,直接尝试从中删除key
if (node.isLeaf()) {
return node.getKeys().remove(key);
}
int pos = node.position(key);
if (pos == node.getSize() || node.getKeyAt(pos).compareTo(key) != 0) {
// node不包含关键字key
BNode<K> childNode = node.getChildAt(pos);
if (childNode.getSize() < minDegree) {
// childNode关键字个数小于minDegree,需要增加
BNode<K> leftSibling = null, rightSibling = null;
if (pos > 0 && (leftSibling = node.getChildAt(pos - 1)).getSize() > minDegree - 1) {
// 若childNode左兄弟中的关键字个数大于minDegree-1
// 首先用左兄弟中最大的关键字去替换node中的相应结点
K maxK = leftSibling.getKeys().removeLast();
K tempK = node.setKeyAt(pos - 1, maxK);
childNode.getKeys().addFirst(tempK);
// 移动child(若存在child)
if (!leftSibling.getChildren().isEmpty()) {
BNode<K> maxNode = leftSibling.getChildren().removeLast();
childNode.getChildren().addFirst(maxNode);
}
} else if (pos < node.getSize() && (rightSibling = node.getChildAt(pos + 1)).getSize() > minDegree - 1) {
// 同上
K minK = rightSibling.getKeys().removeFirst();
K tempK = node.setKeyAt(pos, minK);
childNode.getKeys().addLast(tempK);
// 移动child(若存在child)
if (!rightSibling.getChildren().isEmpty()) {
BNode<K> minNode = rightSibling.getChildren().removeFirst();
childNode.getChildren().addLast(minNode);
}
} else {
// childNode的左右兄弟(若存在)中的关键字都小于minDegree
// 合并
if (leftSibling != null) {
childNode.getKeys().addFirst(node.getKeyAt(pos - 1));
childNode.getKeys().addAll(0, leftSibling.getKeys());
childNode.getChildren().addAll(0, leftSibling.getChildren());
node.getKeys().remove(pos - 1);
node.getChildren().remove(pos - 1);
} else if (rightSibling != null) {
childNode.getKeys().addLast(node.getKeyAt(pos));
childNode.getKeys().addAll(rightSibling.getKeys());
childNode.getChildren().addAll(rightSibling.getChildren());
node.getKeys().remove(pos);
node.getChildren().remove(pos + 1);
}
if (node == root && node.getSize() == 0) {
// 根结点为空,需要删除根结点
height--;
root = root.getChildAt(0);
}
}
}
// 此时一定能保证childNode中的关键字个数大于t-1
return delete(childNode, key);
}
// node包含关键字key
BNode<K> leftChildNode = node.getChildren().get(pos);
if (leftChildNode.getSize() > minDegree - 1) {
K maxKey = leftChildNode.getKeys().getLast();
node.getKeys().set(pos, maxKey);
return delete(leftChildNode, maxKey);
}
BNode<K> rightChildNode = node.getChildren().get(pos + 1);
if (rightChildNode.getSize() > minDegree - 1) {
K minKey = rightChildNode.getKeys().getFirst();
node.getKeys().set(pos, minKey);
return delete(rightChildNode, minKey);
}
leftChildNode.getKeys().add(node.getKeyAt(pos));
leftChildNode.getKeys().addAll(rightChildNode.getKeys());
leftChildNode.getChildren().addAll(rightChildNode.getChildren());
node.getKeys().remove(pos);
node.getChildren().remove(pos + 1);
return delete(leftChildNode, key);
}
以上代码都是根据前面的讨论写出来的,这里也不再多做说明。
该过程尽管看起来很复杂,但根据前面的分析我们可以得出,对于一棵高度为的B树,它只需要次磁盘操作,所需CPU时间是。
5. BTtreeMap
基于以上,我们可以自己实现一个Map,一下是完整的Java实现代码:
import java.io.Serializable;
import java.util.*;
public class BTreeMap<K extends Comparable<K>, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable {
private Node root;
private int size;
private int height;
private int minDegree, min, max;
public BTreeMap() {
this(3);
}
public BTreeMap(int minDegree) {
if (minDegree < 0) {
throw new IllegalArgumentException("minDegree must be greater than 0!");
}
this.minDegree = minDegree;
this.min = minDegree - 1;
this.max = 2 * minDegree - 1;
this.root = new Node(true);
}
@Override
public V get(Object key) {
return search(root, (K) key); // 简单处理,直接强转
}
private V search(Node node, K key) {
Iterator<Node> childrenIterator = node.children.iterator();
int i = 0;
for (Entry<K, V> entry : node.keys) {
Node child = childrenIterator.hasNext() ? childrenIterator.next() : null;
int compareRes = entry.getKey().compareTo(key);
if (compareRes == 0) {
return entry.getValue();
}
if (compareRes > 0 || i == node.keysSize() - 1) {
if (compareRes > 0) {
child = childrenIterator.hasNext() ? childrenIterator.next() : null;
}
if (node.isLeaf) return null;
return search(child, key);
}
i++;
}
return null;
}
@Override
public V put(K key, V value) {
// 判断根结点是否是满的
if (root.isFull()) {
// 若是满的,则构造出一个空的结点,作为新的根结点
Node newNode = new Node(false);
newNode.addChild(root);
Node oldRoot = root;
root = newNode;
splitNode(root, oldRoot, 0);
height++;
}
Entry<K, V> entry = insertNonFull(root, new Entry<K, V>(key, value));
return entry == null ? null : entry.getValue();
}
/**
* 将关键字k插入到以node为根结点的子树,必须保证node结点不是满的
*
* @param node 要插入关键字的子树的根结点(必须保证node结点不是满的)
* @param key 待插入的关键字
*/
private Entry<K, V> insertNonFull(Node node, Entry<K, V> key) {
int i = 0;
// 因为node.keys使用的是LinkedList,因此使用迭代器迭代效率比较高
Iterator<Node> childrenIterator = node.children.iterator();
for (Entry<K, V> entry : node.keys) {
Node child = childrenIterator.hasNext() ? childrenIterator.next() : null;
int compareRes = key.compareTo(entry);
if (compareRes == 0) {
// key相等的情况,替换
return node.keys.set(i, key); // TODO 效率不高!
}
if (compareRes < 0 || i == node.keysSize() - 1) {
if (compareRes > 0) {
i++;
child = childrenIterator.hasNext() ? childrenIterator.next() : null;
}
// 当key < entry 或者 迭代到最后一个元素,此时i指向要插入位置。
if (node.isLeaf) {
node.keys.add(i, key);
size++;
return null;
}
if (child.isFull()) {
Object[] nodeArray = splitNode(node, child, i);
Node leftNode = (Node) nodeArray[0];
Node rightNode = (Node) nodeArray[1];
child = key.compareTo(leftNode.keys.getLast()) <= 0 ? leftNode : rightNode;
}
return insertNonFull(child, key);
}
i++;
}
// node是root,且为null的情况
node.addKey(key);
size++;
return null;
}
/**
* 分裂node的第i个子结点
*
* @param pNode 被分裂结点的父结点
* @param node 被分裂结点
* @param i 被分裂结点在其父结点children中的索引
*/
private Object[] splitNode(Node pNode, Node node, int i) {
int keysSize = node.keysSize();
int ChildrenSize = node.childrenSize();
LinkedList<Entry<K, V>> leftNodeKeys = new LinkedList<Entry<K, V>>(node.keys.subList(0, keysSize / 2));
LinkedList<Node> leftNodeChildren = node.isLeaf ? new LinkedList<Node>() : new LinkedList<>(node.children.subList(0, (keysSize + 1) / 2));
Node leftNode = new Node(leftNodeKeys, leftNodeChildren, node.isLeaf);
LinkedList<Entry<K, V>> rightNodeKeys = new LinkedList<Entry<K, V>>(node.keys.subList(keysSize / 2 + 1, keysSize));
LinkedList<Node> rightNodeChildren = node.isLeaf ? new LinkedList<Node>() : new LinkedList<>(node.children.subList((ChildrenSize + 1) / 2, ChildrenSize));
Node rightNode = new Node(rightNodeKeys, rightNodeChildren, node.isLeaf);
Entry<K, V> middleKey = node.getKey(keysSize / 2);
pNode.addKey(i, middleKey);
pNode.setChild(i, leftNode);
pNode.addChild(i + 1, rightNode);
// return new Node[]{leftNode, rightNode}; TODO: new 不出来
return new Object[]{leftNode, rightNode};
}
@Override
public Set<Map.Entry<K, V>> entrySet() {
return null;
}
/**
* B树的结点类
*/
private class Node {
private LinkedList<Entry<K, V>> keys;
private LinkedList<Node> children;
private boolean isLeaf;
private K data;
private Node(boolean isLeaf) {
this(new LinkedList<Entry<K, V>>(), new LinkedList<Node>(), isLeaf);
}
private Node(LinkedList<Entry<K, V>> keys, LinkedList<Node> children, boolean isLeaf) {
this.keys = keys;
this.children = children;
this.isLeaf = isLeaf;
}
private boolean isFull() {
return keys.size() == max;
}
/**
* 查找k,返回k在keys中的索引
*
* @param k
* @return
*/
private int indexOfKey(K k) {
return keys.indexOf(k);
}
/**
* 查找关键字在该结点的位置或其所在的根结点在该结点的位置
*
* @param k
* @return i
*/
private int position(Entry<K, V> k) {
int i = 0;
Iterator it = keys.iterator();
for (Entry<K, V> key : keys) {
if (key.compareTo(k) >= 0)
return i;
i++;
}
return i;
}
private boolean addKey(Entry<K, V> k) {
return keys.add(k);
}
private void addKey(int i, Entry<K, V> k) {
keys.add(i, k);
}
private boolean addChild(Node node) {
return children.add(node);
}
private void addChild(int i, Node node) {
children.add(i, node);
}
private Node setChild(int i, Node node) {
return children.set(i, node);
}
private int keysSize() {
return keys.size();
}
private int childrenSize() {
return children.size();
}
private Entry<K, V> getKey(int i) {
return keys.get(i);
}
private Entry<K, V> setKeyAt(int i, Entry<K, V> k) {
return keys.set(i, k);
}
private Node getChild(int i) {
return children.get(i);
}
@Override
public String toString() {
return keys.toString();
}
}
/**
* BEntry封装了key与value,它将做为Node的key
*
* @param <K>
* @param <V>
*/
public static class Entry<K extends Comparable<K>, V> extends SimpleEntry<K, V> implements Comparable<Entry<K, V>> {
public Entry(K key, V value) {
super(key, value);
}
/**
* BEntry的比较其实为key的比较
*
* @param o
* @return
*/
@Override
public int compareTo(Entry<K, V> o) {
return getKey().compareTo(o.getKey());
}
}
}
由于时间关系,暂时只实现了get和put方法,其他方法略。